ThinkingMachine
MN-Coreチャレンジに参加したときの日記
PFNがMN-Coreを開放したプログラミングコンテストを行っているんで参加する。
カレンダー
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
|---|---|---|---|---|---|---|
| 25 | ||||||
| 26 | 27 | 28 | 29 | 30 | 31 | 1 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 |
8/25 とりあえず入門
やったこと
MN-Core勉強会のYouTubeを視聴しました。また、MN-Coreの開発者マニュアルをKindleにダウンロードして読みました。
知見
チップ構造
- チップ -> L2B -> L1B -> MAB -> {PE | MAU} という包括的な構造になっているらしい。
- PE (Processing Element):普通のCPUの延長線上っぽい。
- Matrix Arithmetic Unit:行列演算を行うユニット、転置やMACができるらしい。TPUのシストリックアレイに似たものかもしれない。
- L1B:MABが16個とか32個の集合で、L1B MemoryやL1B Reduction Unitが含まれる。
- L2B:L1Bを8個束ねたものらしい。L2B MemoryやL2B Reduction Unitが含まれる。
メモリ空間の分離
- PEからグローバルメモリにアクセスすることができない。PEからアクセス可能なのはPEが持つメモリ利用域だけ。
- PEでデータを利用するためには、DRAM -> L2B -> L1B -> PEという段階的な転送が必要になる。
演算の制御
- PEに命令発行ユニットがない。
-
PCI Expressから命令を流し込んで実行する。
- 命令の種類
- PE命令
- MAU命令
- L1B命令:L1B <=> MAB間の転送命令
- L2B命令:L2B <=> L1B間の転送命令
- DRAM/PDM命令:L2B <=> DRAM間の転送命令
これらの命令が次のようなVLIWになる。
| PE命令 | MAU命令 | L1B転送命令 | L2B転送命令 | DRAM命令 | |——–|———|————-|————-|———-|
感想とかいろいろ
- 機械学習の性質から決定論的にメモリアクセスを行うのでキャッシュがいらないのかもしれない。
- ハードウェアの機能をソフトウェアに置き換えている。→可塑性が高く、効率的にできる。
- 機械学習のノウハウから強力なコンパイラが構築でき、MN-Coreを効果的に扱えるようになるっぽい。
- PyTorchでGPUのように扱えるソフトウェアスタックが用意されている。
- データパラレルの時代はAll Reduce(データを配布して計算して集める処理)について考えればよかったが、現在のLLMでは直列のパイプラインが重要。
- PFN、IIJ、JAISTが共同研究している。→この前VDECで回ってきたAIプロセッサの公募はもしかしてこれか?
- なんというかCGRAに近い、NAISTで開発されていたEMAXに似ている。
積み残し
それぞれの命令の機能がまだわからない。明日は命令のリストを作ってチェックする。
8/26 開発者マニュアルの読み込み
やったこと
引き続きMN-Coreの開発者マニュアルを読みました。命令数が多すぎて理解できなかったので、完全な命令セットの作成は諦めました。
知見
パッと読んで理解できなかった点について以下のようにまとめました。
PEのメモリ構成がよくわからない
PEに含まれるレジスタファイルなどの名前がよくわからない | メモリ名 | 1PEあたりのメモリ容量 | 読み書き | |———-|———————–|———-| | GRF0 | 256ワード | 1R1W | | GRF1 | 256ワード | 1R1W | | T | 8ワード | 1R1W | | LM0 | 2Ki | 1RW | | LM1 | 2Ki | 1RW | GRFが1R1Wなので、ダブルポンピングメモリかロジックで構成されている可能性があります。
サンプルコードが何をやっているのか分からない
ダウンロードしたjudgeにサンプルコードが含まれていますが、何をしているのかよくわからないので、読み進めています。
/content/judge/example/hello_world/example.vsm
imm ui"0" $n0
imm ui"0x48656c6c" $r2
imm ui"0x6f2c2077" $r3
imm ui"0x6f726c64" $r0
imm ui"0x21000000" $r1
sor $subpeid $n0 $omr1
nop
lpassa $lr2 $lr0/$imr1
nop/2
# d get $lr0n0c0b0m0 1
l1bmrsbor $llr0v $llb0
nop/3
# d get $lb0n0c0b0 1
l2bmrsbor $lb0 $lc0
# d get $lc0n0c0 1
nop/3
mvp/n64i01 $lc0 $d0
nop; wait i01
imm命令
imm命令は即値命令で、即値リテラルを2ワード出力します。
imm ui"0" $n0
について考えるとまずimmuではないのでuオプションは無効である。 次にui”0”は符号ナシの整数型0を表している。RISC-Vだと整数型と浮動小数点型とレジスタが分離されていたりするので、同じレジスタに異なる型のデータを格納できるのは結構意外である。そして$nはLM1レジスタを表しているらしい。続く数字の0はアドレスらしい。 つまり、この命令はLM1の0番地に符号なし整数0を格納するという処理だと思う(多分)
MN-Coreのマニュアルに長語とか単語とか半語とか出てくるが
- 半語 (半精度): 16bit
- 単語 (単精度): 32bit
- 長語 (倍精度): 64bit ということらしい。
それぞれのレジスタの指定方法は次の表の通りである |記号|メモリ種類|アクセスワード| |—|—|—| |$lc|L2BM|長語| |$lb|L1BM|長語| |$llb|L1BM|2 長語| |$r, $s, $m, $n|GRF0,GRF1,LM0,LM1|単語| |$lr, $ls, $lm, $ln|GRF0,GRF1,LM0,LM1|長語| |$llr, $lls, $llm, $lln|GRF0,GRF1,LM0,LM1|2 長語| |$t, $lt|Tレジスタ|長語| |$llt|Tレジスタ|2 長語| もっと細かい設定とかあるがマニュアルを自分で読んでほしい
1上の情報に従うと以下の命令はコメントのような感じだと思う
imm ui"0" $n0 #LM1の0番地に半語として0を書き込む
imm ui"0x48656c6c" $r2 #GRF0の2番地に半語として"0x48656c6c"を書き込む
imm ui"0x6f2c2077" $r3 #GRF0の3番地に半語として"0x6f2c2077"を書き込む
imm ui"0x6f726c64" $r0 #GRF0の0番地に半語として"0x6f726c64"を書き込む
imm ui"0x21000000" $r1 #GRF0の1番地に半語として"0x21000000"を書き込む
#### ALU命令
sor $subpeid $n0 $omr1
sorはor命令に対して、精度指定のsがついているため、半精度です。レジスタに 第一オペランドの$subpeidは自分のPEの番号でビット幅は2bitらしいです。PEは4つでL1Bを構成しているからL1B内のアドレスってことで大丈夫かな? 第2オペランドの$n0はLM1の0番地の半語アクセスですね。 最後のオペランドの$omr1マスクレジスタです。マスクレジスタの1番地ってことになりますね。マスクレジスタは条件分岐を実現するための特殊なレジスタであり、ビットの状態によって計算をスキップしたりします。自分のPEが持つIDと0を論理和演算してマスクレジスタに代入していることになりますね。4bitしかないので半語で扱うのかな?
感想とかいろろ
MN-CoreのPEについてわかってきたが、メモリ転送に関しては、まだまだ分からない
積み残し
サンプルコードのまだ読んでない残りの行があるので、明日は残りの行を読んでいきます。
8/27 つづきとか
やったこと
引き続きサンプルコードを読んでいきます。
nop命令
いわゆるnop命令であり、特に何もしないのであるが、MN-Coreでは転送などの待ちをnop命令で調整しないといけないらしい。 nopのあとに/がついていることがあるが、これは複数回動かすことを示すためのシンタックスシュガーらしい
passa命令
コピー命令である。MN-Coreの命令に接頭辞をつけちゃう命名スタイルは正直すごく読みにくい
lpassa $lr2 $lr0/$imr1
というプログラムは、まず接頭辞のlがついているので長語でのコピーを表している。次に第一オペランドである$lr2はコピーもとであろう、GRF0の2番地ということになる。
最後の$lr0/$imr1とあるが、$lr0は書き込み先のレジスタと先頭の番地であり、$imr1は書き込みのマスクであると考えられる。
l1bmr命令
l1bmrsbor $llr0v $llb0
この命令はに L1BM-L2BM 間の転送を行う命令であるのでかなりややこしい。
この命令の構造は以下ののような感じになってる
l1bmr<rrn_opcode> <src> $lb<addr_b>
オペコードの意味を考えると
- <rrn_opcode>は縮約演算していというものでsborはshort型(半語)でborは論理orを表している。
- src orしているのでそれぞれのpeから1ワードづつ読み出して、それぞれのPE番目のデータとPEのメモリのsrcからcycleでインクリメント下値をorを計算しているっぽい?難しすぎる。
意味がわからなすぎるので疑似コードを頑張って読んでいく
for cycle = 0:4 //4回繰り返す
forall group,l2b,l1b //すべてのブロックで演算を行う。
LongWord data[4] //配列の宣言
data[:] = get_unit_value(rrn_opcode) //PEメモリのオペランドの単位元を入れる。orだったら全部0
forall mab,pe //すべてのmabおよびpeで演算をする?
//dataうちPEのIDが対応するアドレスに対してdataのPEのIDが対応するものと、サイクル番目のアドレスのデータを読み出してor
data[pe] = rrn_opcode(data[pe], MEM[group][l2b][l1b][mab][pe].refer_pemem(src,cycle))
uint_t dst_addr = addr_b + cycle * 4 //出力アドレスをインクリメント
MEM[group][l2b][l1b].l1bm[dst_addr:dst_addr+4] = data[0:4] //4こベクトルでコピー
l2bmr命令
mvp命令
mv命令は複雑らしい、PFNの人が文法が複雑だって言うんだから俺に理解するのは無理だろう mvp/n64i01 $lc0 $d0 まずmvのあとについているn64は転送サイズが64byteであることを表しているらしい。その後のi01はタグ番号らしい。 第2オペランドが転送元であるL2BM、第3オペランドDRAMであり転送先を表す。 つまりこの命令はL2BMの0番地からDRAMの0番地へ転送するという認識でいいのかな?
全体を読み直す
imm ui"0" $n0 # LM1の0番地に半語として0を書き込む
imm ui"0x48656c6c" $r2 # GRF0の2番地に半語として"0x48656c6c"を書き込む
imm ui"0x6f2c2077" $r3 # GRF0の3番地に半語として"0x6f2c2077"を書き込む
imm ui"0x6f726c64" $r0 # GRF0の0番地に半語として"0x6f726c64"を書き込む
imm ui"0x21000000" $r1 # GRF0の1番地に半語として"0x21000000"を書き込む
sor $subpeid $n0 $omr1 #半精度(半語)で自分のPE番号と、LM1の0番地(つまり0)とorを計算する
nop # 1サイクル休み
lpassa $lr2 $lr0/$imr1 # GRF0の2番地の内容をGRF0の0番地にマスクして長語でコピーする(2を先頭として4アドレス行われる?)
nop/2 # 2サイクル休み
# d get $lr0n0c0b0m0 1
l1bmrsbor $llr0v $llb0 #GRF0の0番地を2長語でorしてGRF1の0番地に書き込む
nop/3
# d get $lb0n0c0b0 1
l2bmrsbor $lb0 $lc0
# d get $lc0n0c0 1
nop/3
mvp/n64i01 $lc0 $d0
nop; wait i01
感想
RISCしか触ってこなかったので、正直なところ意味不明過ぎて困惑している。RISC-Vのベクトル命令ですら混乱するのに、なんやこれ?
積み残し
例題をときたかったけど、まだ終わってない。明日からコンテスト開場なので頑張りたい。
8/27 例題解くぞ!
とりあえず例題をときました。今日は説明が面倒臭いので、とりあえず初見で思いついたクソ解法を貼っておきます。 例題の3問は解答に関してネタバレが許可されているんですが、それ以降の問題はネタバレが禁止されています。
なので、明日からの問題は解けたか解けてないかと、学ぶ必要を感じた知識の解説だけ行っていきます。
Welcome
iinc $m[0,1,2,3] $n[0,1,2,3]
iinc $m[4,5,6,7] $n[4,5,6,7]
iinc $m[8,9,10,11] $n[8,9,10,11]
iinc $m[12,13,14,15] $n[12,13,14,15]
inc命令を知らなかったんですが、とりあえずサンプルコードベースに書きました。
Plus2
linc $lm0v $lm0v
nop
nop
linc $lm0v $ln0v
nop
nop
linc $lm8v $lm8v
nop
nop
linc $lm8v $ln8v
nop
nop
linc $lm16v $lm16v
nop
nop
linc $lm16v $ln16v
nop
nop
linc $lm24v $lm24v
nop
nop
linc $lm24v $ln24v
nop
nop
linc $lm32v $lm32v
nop
nop
linc $lm32v $ln32v
頭の悪さがにじみ出ていますね。
A+B
iadd $lm0v $ln0v $lr0v
nop/2
ipassa $lr0v $lm32v
nop/2
iadd $lm8v $ln8v $lr0v
nop/2
ipassa $lr0v $lm40v
nop/2
iadd $lm16v $ln16v $lr0v
nop/2
ipassa $lr0v $lm48v
nop/2
iadd $lm24v $ln24v $lr0v
nop/2
ipassa $lr0v $lm56v
なんか怖いからとりあえずnopを入れるクセがついてしまっています。多分必要以上にnopが入ってるんじゃないかな?
結果
 とりあえず短くは無いですが3つとも解けていますね。疲れた、眠い。明日は
とりあえず短くは無いですが3つとも解けていますね。疲れた、眠い。明日は
8/29 1問解いたぞ!
眠いので今日は前回の問題の最短解をとき、続きの問題を1問だけときました。
一応今回のコンテストの目標は全部の問題を咲いたんじゃなくていいから、解くこととします。
 眠いです。おやすみ。
眠いです。おやすみ。
積み残し
明日は以下の内容について調べて記事にしたいと思います。
- MAUを使った演算
- PEのIDによるマスキング
- nop命令の発生条件
8/30 お勉強するぞ
今日は昨日の積み残しである3つのうち以下の2つだけに関してお勉強します。
- PEのIDによるマスキング
- nop命令の発生条件 2つに絞った理由はMAUは複雑過ぎて今日1日で学ぶのは無理だと思ったからです。
nop命令の発生条件
おさらいとして、nop命令はデータハザードを回避するために挿入されます。
まずデータハザードについてお勉強します。データハザードはパイプラインプロセッサにおいてデータの依存関係を無視した参照が発生した場合に計算結果がおかしくなる現象です。
c = a + b
d = c + a
みたいな計算があった場合にcの計算が終わる前にc + aを始めたら、答えがおかしくなってしまいます。
このような場合cをメモリに書き戻す前に直接aとの加算に接続するフォワーディングや、cの計算が終わるまでパイプラインを休ませるパイプラインインターロックなんかが存在します。MN-Coreはこれらのフォワーディングやパイプラインインターロックの機能を持ちません。通常のRISC-Vであれば、複数の実装で同一のバイナリを実行できなければいけませんが、MN-CoreはMN-Coreしか無いので、そのような操作は事前に予測可能であり、コンパイル時に行えばよいという設計方針のようです。
MN-Coreの開発者マニュアルの3.6.4によると、MN-Coreのデータハザードにはデータ競合とポート競合の二種類があるようです。データ競合は書き込みが終わるまで待たないのに読み出してしまうことによって発生する競合。ポート競合はアドレス線などのハードウェア資源の解法を待たなければいけないことによって発生するようです。
MN-Coreにはたくさんの階層のメモリが存在しますが、L1BMやL2BMのような階層をまたぐ話はまた今度にします。
PEメモリ書き込み=>PEメモリ読み出し
いままでプログラミングしてきたものを見るとわかると思いますが、PE間のデータ転送においてもnopが必要になります。 ここでPEに搭載されてるメモリの表を思い出します。
| メモリ名 | 読み書き |
|---|---|
| GRF0 | 1R1W |
| GRF1 | 1R1W |
| T | 1R1W |
| LM0 | 1RW |
| LM1 | 1RW |
読み書きが1RWと1R1Wの二種類が存在しますね。この表記はRAMの読み書き機能を表現するための表記で1R1Wは1サイクルで1回の読み出しと、1回の書き込みに対応していることを表します。つまりデュアルポートSRAMってやつです。 次に1RWですが、これは1サイクルに1回の読み出しか、もしくは書き込みが可能なことを表しています。
- LM0/LM1(おそらくTも)に対しては書き込んだあと、ポート衝突により2ステップ開けてから出ないと読み出しを開始できない。
- GRF0/GRF1に書き込んだあとは、データ競合により1ステップ開けてから出ないと同じアドレスからは読み出し書き込みができない、しかし異なるアドレスであれば同時に読み書きできる.
- Tレジスタに書き込んだあとはデータ競合により1ステップ開けてからでないと読み出しを開始できない。
ということらしいです。メモリの構造から考えてもこれらの制約は理にかなってますね。 色々サンプルコードを示して実験してみたいですが、時間が無いので今日はこのくらいにしておきます。
PEのIDによるマスキング
MN-CoreにはOMRというマスクレジスタが存在します。このレジスタはデータを保持するためのレジスタではなく、フラグを保持するためのレジスタであり、PEのメモリ書き込み時または、演算結果出力時に指定した箇所についての書き込みのスキップやゼロフラッシュが可能です。これにより擬似的な条件分岐が実現できます。なんだかSIMTみたいですね。
マスクレジスタを使うことでPEメモリの殆どにマスクを適用可能なようです。 このレジスタは出力専用のようでMAU命令かALU命令でのみ書き込みが可能なようです。
以下のコードはマニュアルからの引用ですが、/のあとに1になっているサイクルのみで書き込みが行われるようです。面白いですね。 ‘’’ lpassa $lm0v $lr0v/0001 lpassa $lm8v $lr8v/1000 ‘’’
積み残し
5問目の解法は頭の中に出来上がってるので実装する。
9/1 解く
やったこと
問題の内容について触れられませんが、judge.pyはテストケースが無いと実行できないので、プログラムを実行するためだけのプログラムを書きました。judge.pyと同じ階層に置いてください。
import argparse
import subprocess
import os
def run_commands(vsm_path, assembler_path, emulator_path):
asm_path = "sample.asm"
dmp_path = "sample.dmp"
try:
# アセンブルのコマンドを実行
assemble_cmd = f"{assembler_path} {vsm_path} > {asm_path}"
subprocess.run(assemble_cmd, shell=True, check=True)
# エミュレートのコマンドを実行
emulate_cmd = f"{emulator_path} -i {asm_path} -d {dmp_path}"
subprocess.run(emulate_cmd, shell=True, check=True)
# 結果の表示
with open(dmp_path, 'r') as dmp_file:
print(dmp_file.read())
finally:
# 生成されたファイルを削除
if os.path.exists(asm_path):
os.remove(asm_path)
if os.path.exists(dmp_path):
os.remove(dmp_path)
def main():
parser = argparse.ArgumentParser(description="Run assembly and emulate process for a VSM file.")
parser.add_argument("vsm", help="Path to the VSM file to process", type=str)
parser.add_argument("--assembler", help="Path to the assembler binary", default="judge-py/mncore2_emuenv/assemble3", type=str)
parser.add_argument("--emulator", help="Path to the emulator binary", default="judge-py/mncore2_emuenv/gpfn3_package_main", type=str)
args = parser.parse_args()
run_commands(args.vsm, args.assembler, args.emulator)
if __name__ == "__main__":
main()
実行は以下のように行ってください。
python3 judge-py/just_run.py example/hello_world/example.vsm
5問目
5問目のプログラムにちょっとした間違いがあったので、それを修正したら一気に通りました。
6問目
難しくはなかったです。MAU命令の勉強になりました。

9/2 引き続き2問解く
今日の順位:131位/431
やったこと
今日も2問ときました。今のところ解いている問題は全部練習問題なんであんまり達成感は無いです。
7問目
割とかんたんで調子にノリました。特に迷うようなこともなかったです。
8問目
最初はこんなのは無理だろと思いましたが、頑張って解きました。shortestは黒魔術だと思います。どうやってるんだ?
感想とか
そすうぽよ氏とかmaspy氏とかAtcoderで聞き覚えがある名前がたくさん出てくるので凹みますね。「この人らに絶対勝てないじゃん」って! 雑魚らしく最終目標100位以内を目指して頑張っていきます。
9/3 ヘトヘト
今日の順位:108位/456
折り返し地点。100位の壁が見えてきました。
やったこと
今日も2問ときました。ヘトヘトです。MN-Coreは挙動が分かりづらいので、バスを示したグラフィカルシミュレータが必要だと思います。

9問目
以前深層学習のライブラリを作っていたので、この手の計算は得意です。
10問目
沼った。とてもつらかった。
感想とか
ヘトヘトです。 あと、2問くらいはチュートリアルが続きそうですが、2日に1問くらいのペースになりそうです。 同じ操作が命令がv命令とと普通の演算命令で実現できたりするのでそういうのをまとめていきたいですね。
9/4 並列化について考える
問題の内容と解法については触れられませんが、MN-Coreの構造と、転送、縮約命令について理解しないと、これ以上進めなそうなので、今日はこれらの機能についてお勉強します。
分かんねぇこと 今まで1個だけのMABの中の話だけ見ていたので、ここでプロセッサ全体を意識する必要が出てきて脳が千切れそうになってます。現状何が分からんのかわからなかったので、調べ直して箇条書きすると以下の概念が分からないことがわかりました。今日は最初の一つについてだけ考えます。
- MN-Coreの構造
- MN-CoreLM0やL1BML2BMといったメモリ間の転送
- 縮約命令とか言う謎の概念。
MN-Coreの構造
MN-Coreは最初の頃にも説明しましたが、独立したアドレスを持つ階層構造を持っています。公式の開発マニュアルにはグラフィカルな説明が殆どないので以下の動画を参考にしてます。
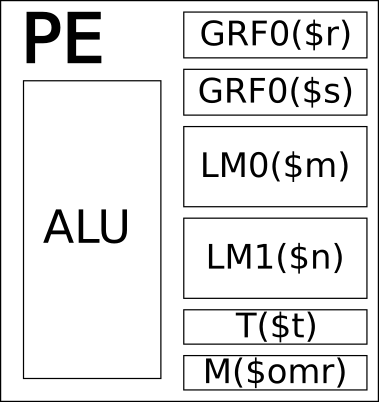
PEの構造
とりあえずPEの構造について説明していきます。おさらいになりますが、私の理解ではPEは以下のような構造をしています。この他にXYレジスタというのも存在するんですが、これがPE内にあるかわからないので今回は省略します。
 でそれぞれの構成要素についてお話していきます。
でそれぞれの構成要素についてお話していきます。
-
ALU ALUは整数演算を行います。DoubleやFloatの演算はMAUでおこないます。
-
GRF(General Register File) GRFはレジスタです。いわゆるレジスタファイルであり、メモリからロードしたデータを保存しておき高速にアクセスして使います。
-
LM(Local Memory) ローカルメモリーです。コンテストでのデータは基本的に最初はここに格納されていると思います。LMとGRFの違いはアクセス速度で、LMはデュアルポートSRAMでは無いようなのでアクセス時間が長いです。なので、何度も使うデータ。例えば累積される計算値などはGRFに置いたほうが良いようです。
-
T(Temporary Register) 名前がTemporaryとついていますが何がテンポラリなのかよくわからないです。関節参照につかわれるレジスタで、必ず2ワードアクセスになるとい特殊な性質がありますが、構造とは関係ないので説明しません。
-
M(マスクレジスタ) 公式の資料には書いてありませんが、データ書き込みにマスクをするのに追加います。
この他にXYレジスタというものがありますが省略します。このレジスタはMAUを使ったときにしか使いません。
こんな感じでPEはたくさんのSRAMによって構成されてます
MAB
MABは行列演算や浮動小数点演算を行うMABとPEが4つセットになったものです。以下のような構造というか構成をしています。

MAUは行列を行うユニットです。ここまで説明出してきませんでしたがPEには番号が振られており(というかすべての階層のブロックに番号はある)MAUは倍精度の演算は1度に2要素までしかできないので、単精度だとすべてのPEに対して行える命令(fvfnaなど)も倍精度だと(dvfmaなど)ではuとdを使って最初の2つのPEに対して演算を行うか、その他2つのPEで演算を行うか指定してあげる必要があります。
MAUの機能
- ベクトル積(A ✕ B + C)もしくわ(A ✕ B)を半制度、単精度、倍精度の三種類で行う。
-
行列積和 (A ✕ **行列レジスタ{x y}** + C)を半精度、単精度、倍精度、疑似単精度で行う - 行列レジスタの書き込み
- 行列レジスタの転置読み出し
L1B/L2Bの構造
L1BはMABを16個束ねたものです。l1bのメモリへのアクセスはなんか厄介で苦手ですね。
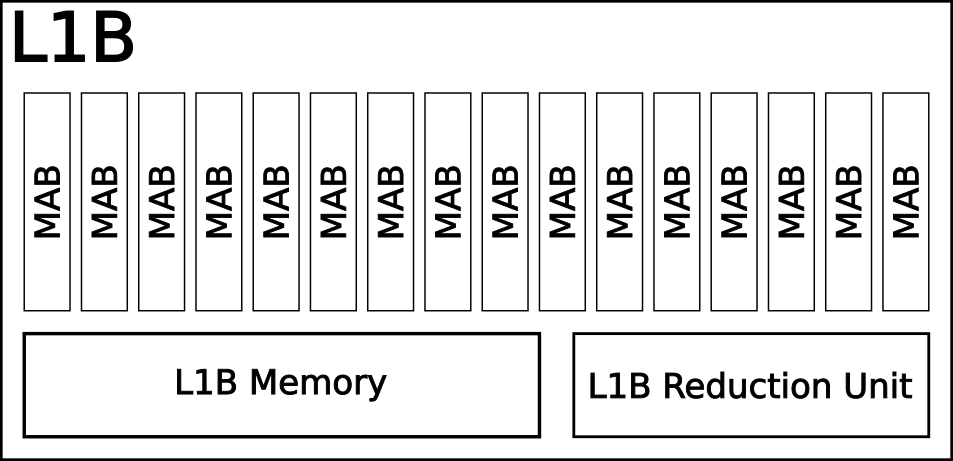 L2BはL1Bを8個集めたものです。
L2BはL1Bを8個集めたものです。
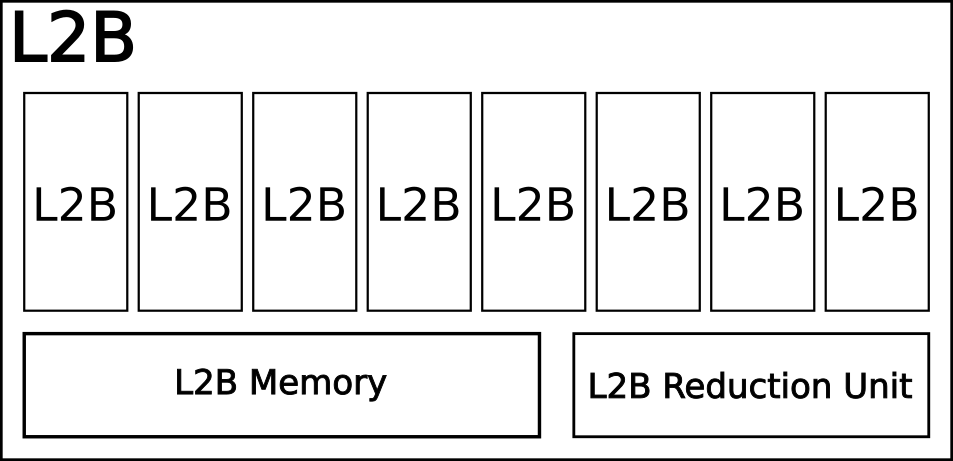
- L*B Memory:L1Bメモリ及びL2Bメモリはそれぞれの階層のローカルメモリです。もしPEからL2Bにデータを転送したい場合PEのLM->L1B->L2Bというパイプライン的に実行する必要があります。
- L*B Reduction Unit:このモジュールに関してほとんど説明がなかったのですが。おそらく縮約命令に関わるものだと思います。縮約がなにかわかってないんですがHPCでいうAll Reduce的なやつかなぁ。
積み残し
残りの2項目に関しては明日まとめます。